Contexto
Estaba trabajando en un web site con wordpress y necesitaba modificar un archivo php del tema que se estaba usando en ese momento, pero estaba realmente distraído con mi mente en otro lugar y aunque acostumbro hacer una copia del archivo antes de editarlo para poder dejarlo como estaba en caso de algo salga mal, esta vez no lo hice ¡GRAVE ERROR!El problema
Reemplace el contenido del archivo de estilos principal (style.css) del tema con código php, para cuando me di cuenta de mi terrible error ya había guardado el archivo y no podía usar el historial de deshacer para restaurar el archivo a su forma anterior y entonces me doy cuenta de que no saqué la acostumbrada copia de respaldo. El problema era serio por que destruí un archivo importante y no tengo una forma obvia de restaurarlo y reescribirlo tomaría horas si es que era posible dejar todo como estaba...La solución
Primero lo primero ¡No hay que entrar en pánico! se piensa mejor calmado.Busqué en google por alguna forma de restaurar mi archivo y encontré que había una forma de recuperar lo usando la cache del navegador, como había estado revisando los cambios al sitio en varios navegadores a saber: chrome, firefox y opera tenía al menos una copia en la cache de alguno de esos, por supuesto no podía volver a abrir el sitio en uno de esos navegadores porque corría el riesgo de actualizar la cache y perder mi ultima esperanza de no tener que reescribir el contenido perdido por mi error.
Encontré en esta guía que existe un script mencionado aquí que te permite recuperar archivos de texto plano a partir del cache de firefox o chrome sin embargo en la primera guía dan una versión que permite recuperar archivos comprimidos usando gzip.
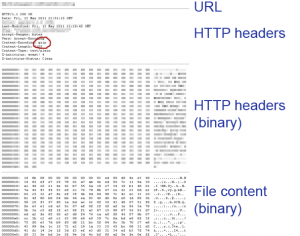
Para entrar al cache de firefox, chrome u opera debemos poner "about:cache" sin las comillas en el campo de dirección del navegador respectivo, a continuación algunos ejemplos de lo que muestran dichos navegadores:
- firefox Version 24.0:

- Chromium Versión 28.0.1500.71 Ubuntu 13.04 (28.0.1500.71-0ubuntu1.13.04.1):

- Opera Version 12.16:




Lo que tenemos que hacer es escribir el siguiente script en un archivo php en nuestro disco duro y llamarlo por ejemplo restore.php:
<?php
// cache.log is a copy of chrome cache page with only the file content section
$cacheString = file_get_contents("cache.log");
$matches = array();
preg_match_all('/\s[0-9a-f]{2}\s/', $cacheString, $matches);
$f = fopen("t.bin","wb");
foreach ($matches[0] as $match)
{
fwrite($f,chr(hexdec($match)));
}
fclose($f);
ob_start();
readgzfile("t.bin");
$decoded_data=ob_get_clean();
echo $decoded_data;
Luego escribimos el texto hexadecimal tomado del cache de nuestro navegador en un archivo llamado cache.log ubicado junto a restore.php, si deciden usar un nombre de archivo diferente al indicado deben ajustar el script restore.php.
Finalmente ejecutamos restore.php para obtener el archivo original (en la consola) a partir del archivo cache.log:
php restore.php
En mi caso particular usé el siguiente comando, para almacenar el texto en un archivo css:
php restore.php > style.css
Extra
Nunca se sabe cuando un script como este puede ser útil así que cree un proyecto en github y subí ambas versiones, a saber: la que recupera texto plano y la que recupera archivos comprimidos con gzip en un solo archivo que puede ser ejecutado de la siguiente forma:php restore_from_cache.php > restored_file
Conclusión
- Siempre mira dos veces lo que estas editando para estar seguro que es el archivo correcto
- Aunque estés seguro de que es el archivo correcto siempre guarda un respaldo antes de hacer tus cambios
- En caso de desastre y si tienes la suerte de que tu o alguien más tenga el archivo en su cache puedes usar los scripts mencionados antes para recuperar el texto original
Saludos y hasta la próxima.